
Análisis Visual de las Encuestas ENIGH 2024 y Datos COVID-19 2025
TRIMESTRE: 25-O
INTEGRANTE: Vicente Cruz Monroy
El siguiente trabajo es realizado por alumnos de la Licenciatura en Economía de la Universidad Autónoma Metropolitana, Unidad Xochimilco, cualquier duda o aclaración mandar un correo a: economia@correo.xoc.uam.mx
En este trabajo realizamos un analisis visual de los datos ENIGH y COVID. Los datos ENIGH son del año 2024 y los datos de COVID-19 son el año *2025**. Estos datos se trabajaron con la paquetería tidyverse.
Histograma de sexo edad simulado
Realizamos un hitograma simulado a partir de dos vectores de edad y sexo, depués se convirtio en un dat frame y se finalizó con un grafica de histograma.

Gráfica de tabla de contingencia
Creamos una tabla de contingencia para educación del jefe del hogar y estatus socieconómico, para posteriormente hacer un gráfico de mosaico, que permite demostrar estos datos de una manera simplificada.

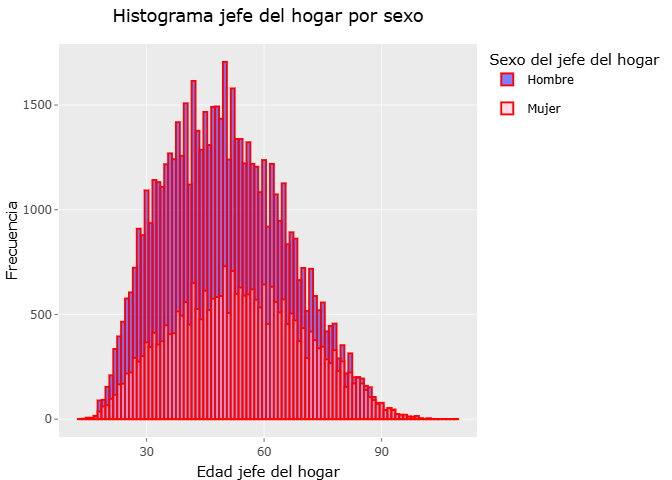
Histograma de edad del jefe del hogar
Realizamos un histograma con los datos seleccionados de edad del jefe del hogar, para posteriormente combinar las paqueterias ggplot2 y plotly, lo que ayuda a tener una mejor forma de mostrar los datos.
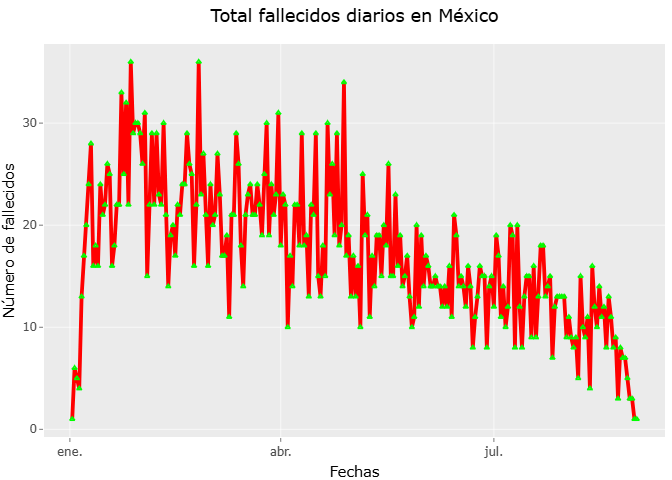
Gráfica de fallecidos diarios
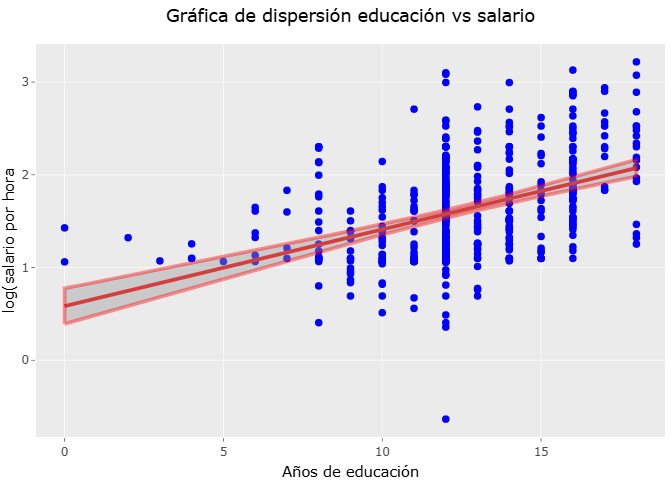
Modelos lineales
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 0.5837727 | 0.0973358 | 5.99751 | 0 |
| educ | 0.0827444 | 0.0075667 | 10.93534 | 0 |
Pruebas diagnósticas

Para acceder a las gráficas interactivas y al detalle del proyecto, utilice el siguiente enlace: https://rpubs.com/Vicente_CM/1374118
INTEGRANTE: Adriana Mercedes Chamorro Melchor
En este trabajo realizamos un analisis visual de los datos ENIGH y COVID. Los datos ENIGH son del año 2024 y los datos de COVID-19 son el año *2025**. Estos datos se trabajaron con la paquetería tidyverse.
Histograma de sexo edad simulado
Realizamos un hitograma simulado a partir de dos vectores de edad y sexo, depués se convirtio en un dat frame y se finalizó con un grafica de histograma.
sexo <- rep(c("Hombre", "Mujer"),40)
# 1) Crear una semilla set.seed()
set.seed(123)
# 2) crear la simulacion copn rnorm()
edad <- rnorm(80,30,10)
hist(edad,
main = "Histograma de edad",
xlab = "Edad",
ylab = "Frecuencia",
col = "purple")
Gráfica de tabla de contingencia
Creamos una tabla de contingencia para educación del jefe del hogar y estatus socieconómico…
# Para establecer etiquetas en el eje x creamos un vector de referencia
Edu <- c("Sin", "Preesc", "Prim-inc", "Prim-comp", "Secu-inc","Secu-com",
"Prep-inc", "Prep-com", "Profe-inc", "Profe-com","Posg")
# Para establecer una leyemda creamos un vector de referencia
esta_socio <- c("Bajo", "Medio bajo", "Medio alto", "Alto")
# Asignar nombres a las filas y columnas
edu_socio2 <- table(datos_enigh$educa_jefe, datos_enigh$est_socio)
rownames(edu_socio2) <- Edu
colnames(edu_socio2) <- esta_socio
# Gráfica de mosaico plot()
plot(edu_socio2,
xlab = "Nivel educativo del jefe del hogar ",
ylab = "Estatus socieconómico",
main= "Relación entre nivel educativo del jefe del hogar y estatus socieconómico",
col= 1:4)
legend("bottomright", esta_socio, cex = 0.2, fill = 1:4, title = "Nivel socioeconómico")
Histograma de edad del jefe del hogar
# Convertimos datos a tipo factor las variables de sexo_jefe
datos_enigh$sexo_jefe <- factor(datos_enigh$sexo_jefe,
levels = c(1,2),
labels = c("Hombre", "Mujer"))
histograma_sexo_edad <-
ggplot(datos_enigh, aes(x=edad_jefe, fill = sexo_jefe)) +
geom_histogram(position = "identity",alpha=0.5,binwidth = 1, col="red") + # stack, dodge
#facet_wrap(~sexo_jefe) +
labs(x=" Edad jefe del hogar", y="Frecuencia", title = "Histograma jefe del hogar por sexo", fill="Sexo del jefe del hogar") +
scale_fill_manual(values = c("Hombre" = "blue", "Mujer" = "pink")) +
theme(plot.title = element_text(hjust = 0.5))
ggplotly(histograma_sexo_edad) %>%
layout(hovermode="x unified")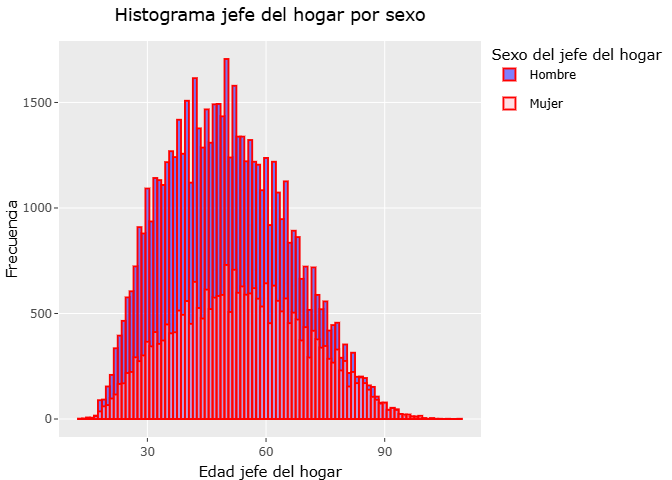
fallecidos_por_fecha <- datos_covid %>%
filter(!is.na(FECHA_DEF)) %>% #filter(fecha_def != "9999-99-99")
# mutate(fecha_def = as_date(fecha_def))
count(FECHA_DEF, name = "Fallecidos_diarios") %>%
arrange(FECHA_DEF) %>%
mutate(Acumulado = cumsum(Fallecidos_diarios))
grafica_falle_diar <- ggplot(fallecidos_por_fecha, aes(x=FECHA_DEF, y=Fallecidos_diarios)) +
geom_line( col="pink", size=1, linetype = 1, alpha=1) +
geom_point( col="purple", size=1, shape=2, alpha=1) +
labs(title = "Total fallecidos diarios en México",
subtitle = " del 01-01-2025 al 31-08-2025",
x="Fechas",
y="Número de fallecidos") +
theme(plot.title = element_text(hjust = 0.5))
# Gráfica dinámica
ggplotly(grafica_falle_diar) %>%
layout(hovermode="x unified")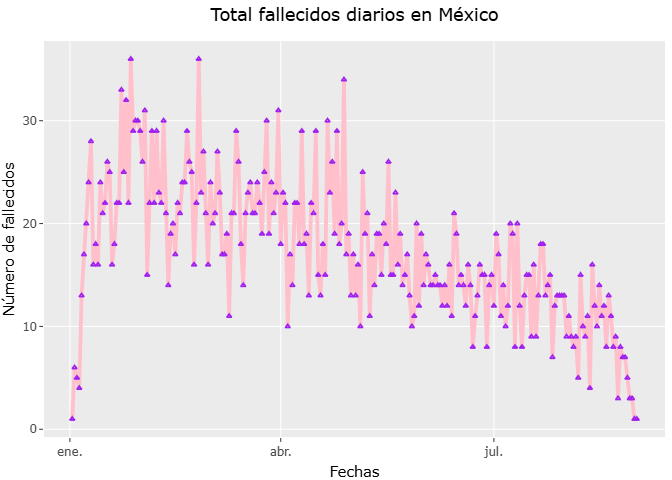
Modelos lineales
modelo_1_graf <- ggplot(wage1, aes(x=educ, y=lwage)) +
geom_point(color="pink") +
geom_smooth(method = "lm", se= TRUE, col="green", linetype=1, linewidth=1) +
labs(title = "Gráfica de dispersión educación vs salario",
x= "Años de educación",
y= "log(salario por hora") +
theme(plot.title = element_text(hjust = 0.5))
ggplotly(modelo_1_graf)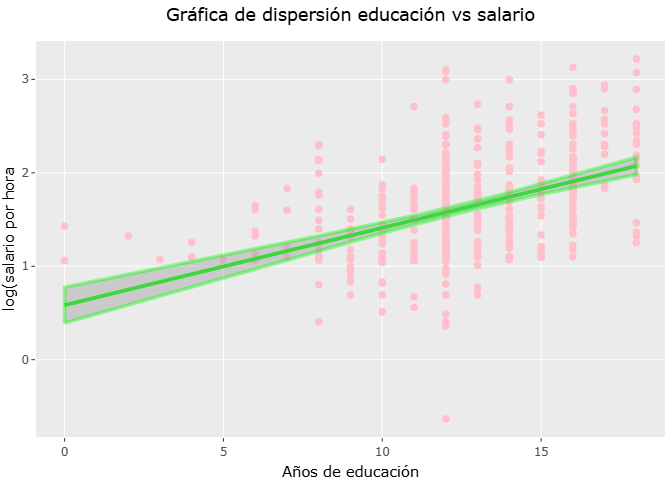
modelo_1 <- lm(lwage ~ educ, data = wage1)
#summary(modelo_1)
# library(knitr)
coefficients(summary(modelo_1)) %>%
kable()| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 0.5837727 | 0.0973358 | 5.99751 | 0 |
| educ | 0.0827444 | 0.0075667 | 10.93534 | 0 |
Pruebas diagnósticas
autoplot(modelo_1, which = 1:3,
nrow = 3,
ncol = 1)
Para acceder a las gráficas interactivas y al detalle del proyecto, utilice el siguiente enlace: https://rpubs.com/adrianamcm18/1374119
INTEGRANTE: Maria Fernanda Tenorio Chilapa
datos_covid <- read.csv("COVID19MEXICO_25.csv")
datos_enigh <- read.csv("conjunto_de_datos_concentradohogar_enigh2022_ns.csv")Visualización Estadística con RStudio: Análisis de COVID-19 y ENIGH
En este trabajo realizamos un análisis visual de los datos de ENIGH 2024 y COVID 2025. Estos datos se trabajaron desde la paquetería ‘tydiverse’
Histograma de edad simulado
En esta sección se construyó un histograma a partir de datos simulados utilizando dos vectores extraídos de la ENIGH: edad y sexo. Posteriormente, ambos vectores se integraron en un data frame para facilitar su manipulación y análisis dentro de RStudio. Con esta base de datos se generó una gráfica de histograma, la cual permite visualizar la distribución de la variable de edad y observar su comportamiento general dentro de la población analizada.
sexo <- rep(c("Hombre", "Mujer"),40)
# 1) Crear una semilla set.seed()
set.seed(123)
# 2) crear la simulacion copn rnorm()
edad <- rnorm(80,30,10)
hist(datos_enigh$edad_jefe,
freq=F,
main = "Histograma de edad",
xlab = "Edad",
ylab = "Frecuencia",
col = "orange",
breaks = 8)
lines(density(datos_enigh$edad_jefe, bw=4), col="red", lwd=2.5)
Gráficas de tabla de contigencia
En esta parte se construye una tabla de contingencia con el propósito de analizar la relación entre el nivel educativo del jefe del hogar y su estatus socioeconómico, utilizando los datos provenientes de la ENIGH 2024.
# Para establecer etiquetas en el eje x creamos un vector de referencia
Edu <- c("Sin", "Preesc", "Prim-inc", "Prim-comp", "Secu-inc","Secu-com",
"Prep-inc", "Prep-com", "Profe-inc", "Profe-com","Posg")
# Para establecer una leyemda creamos un vector de referencia
esta_socio <- c("Bajo", "Medio bajo", "Medio alto", "Alto")
# Asignar nombres a las filas y columnas
edu_socio2 <- table(datos_enigh$educa_jefe, datos_enigh$est_socio)
rownames(edu_socio2) <- Edu
colnames(edu_socio2) <- esta_socio
# Gráfica de mosaico plot()
plot(edu_socio2,
xlab = "Nivel educativo del jefe del hogar ",
ylab = "Estatus socieconómico",
main= "Relación entre nivel educativo del jefe del hogar y estatus socieconómico",
col= 1:4)
legend("bottomright", esta_socio, cex = 0.65, fill = 1:4, title = "Nivel socioeconómico")
Prueba de independencia chi-cuadrado
Después de construir la tabla de contingencia para analizar la distribución conjunta de las variables seleccionadas, es necesario evaluar si la asociación observada entre ellas puede atribuirse al azar o si existe evidencia estadística de una relación real. Para ello se utiliza la prueba de independencia chi-cuadrado, una herramienta ampliamente empleada en el análisis de variables categóricas.
##
## Pearson's Chi-squared test
##
## data: edu_socio2
## X-squared = 17837, df = 27, p-value < 2.2e-16Histograma de edad del jefe del hogar
En este segmento se presenta un histograma de la edad del jefe del hogar, diferenciando la distribución según el sexo. El histograma elaborado muestra cómo se distribuyen las edades entre hombres y mujeres jefes de hogar, permitiendo identificar similitudes, diferencias y patrones relevantes en la estructura demográfica de los hogares. Además, la gráfica interactiva facilita explorar con mayor precisión las frecuencias y rangos de edad dentro de cada grupo.
# Convertimos datos a tipo factor las variables de sexo_jefe
datos_enigh$sexo_jefe <- factor(datos_enigh$sexo_jefe,
levels = c(1,2),
labels = c("Hombre", "Mujer"))
histograma_sexo_edad <-
ggplot(datos_enigh, aes(x=edad_jefe, fill = sexo_jefe)) +
geom_histogram(position = "identity",alpha=0.5,binwidth = 1, col="red") + # stack, dodge
#facet_wrap(~sexo_jefe) +
labs(x=" Edad jefe del hogar", y="Frecuencia", title = "Histograma jefe del hogar por sexo", fill="Sexo del jefe del hogar") +
scale_fill_manual(values = c("Hombre" = "blue", "Mujer" = "pink")) +
theme(plot.title = element_text(hjust = 0.5))
ggplotly(histograma_sexo_edad) %>%
layout(hovermode="x unified")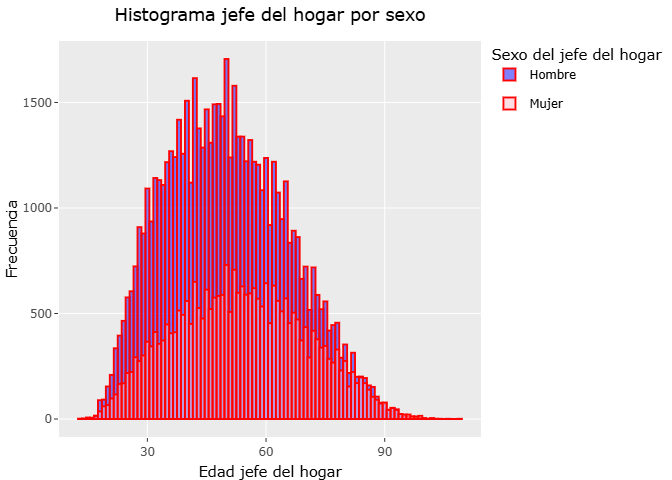
Gráfica de fallecidos diarios
En este bloque analizamos la evolución diaria de fallecimientos asociados a COVID-19 es fundamental para comprender la magnitud y el comportamiento temporal de la pandemia en México.En este ejercicio se construyó una serie temporal que muestra el número de fallecidos por fecha de defunción entre el 1 de enero de 2025 y el 31 de agosto de 2025, con el fin de visualizar de manera clara la dinámica diaria de mortalidad durante este periodo.
fallecidos_por_fecha <- datos_covid %>%
filter(FECHA_DEF != "9999-99-99") %>%
mutate(
FECHA_DEF = as.character(FECHA_DEF),
FECHA_DEF = as.Date(FECHA_DEF, format = "%Y-%m-%d") # Intentar conversión
) %>%
filter(!is.na(FECHA_DEF)) %>%
count(FECHA_DEF, name = "Fallecidos_diarios") %>%
arrange(FECHA_DEF) %>%
mutate(Acumulado = cumsum(Fallecidos_diarios))
grafica_falle_diar <- ggplot(fallecidos_por_fecha, aes(x=FECHA_DEF, y=Fallecidos_diarios)) +
geom_line( col="red", size=1, linetype = 1, alpha=1) +
geom_point( col="green", size=1, shape=2, alpha=1) +
labs(title = "Total fallecidos diarios en México",
subtitle = " del 01-01-2025 al 31-08-2025",
x="Fechas",
y="Número de fallecidos") +
theme(plot.title = element_text(hjust = 0.5))
# Gráfica dinámica
ggplotly(grafica_falle_diar) %>%
layout(hovermode="x unified")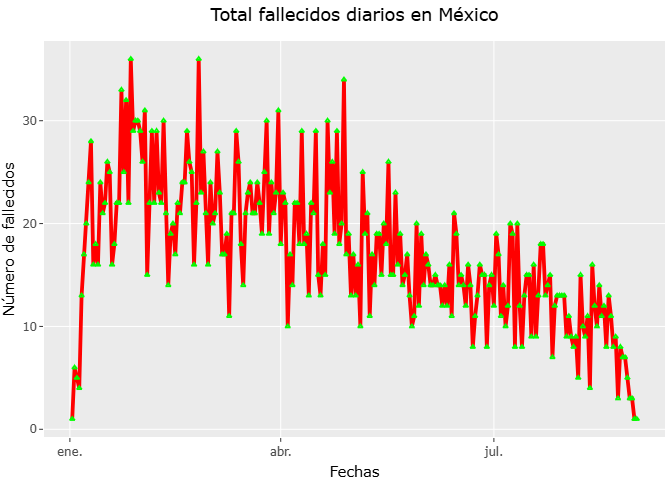
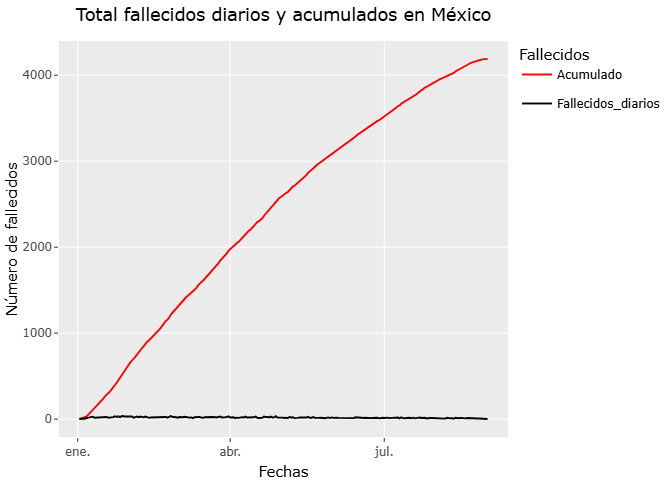
Fallecidos diarios y acumulados
El análisis de la evolución de la mortalidad asociada al COVID-19 resulta fundamental para comprender la dinámica de la pandemia y su impacto en el tiempo. Para ello, una de las herramientas más utilizadas es la representación conjunta de los fallecidos diarios y del acumulado total de defunciones.
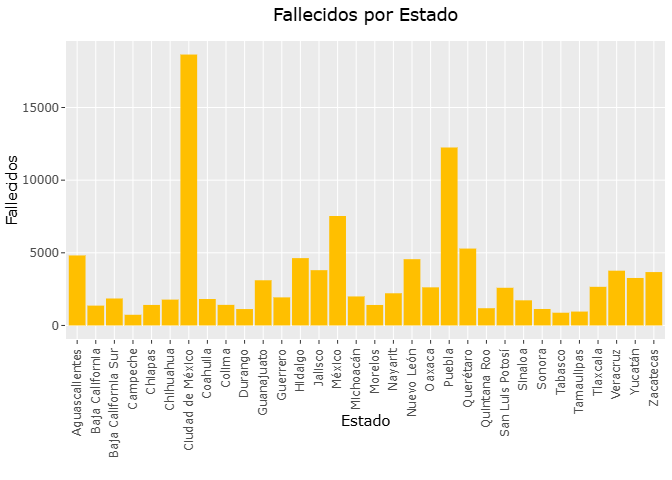
Total fallecidos en el 2025 por Estado
El análisis territorial de la mortalidad por COVID-19 permite identificar diferencias importantes en la forma en que la pandemia afectó a las distintas regiones del país.La gráfica presentada a continuación muestra el número total de defunciones registradas durante 2025 para cada entidad de México.
Modelos lineales 1
En está sección analizamos la relación entre escolaridad y salario a través de los modelos lineales .
modelo_1_graf <- ggplot(wage1, aes(x=educ, y=lwage)) +
geom_point(color="blue") +
geom_smooth(method = "lm", se= TRUE, col="red", linetype=1, linewidth=1) +
labs(title = "Gráfica de dispersión educación vs salario",
x= "Años de educación",
y= "log(salario por hora") +
theme(plot.title = element_text(hjust = 0.5))
ggplotly(modelo_1_graf)## `geom_smooth()` using formula = 'y ~ x'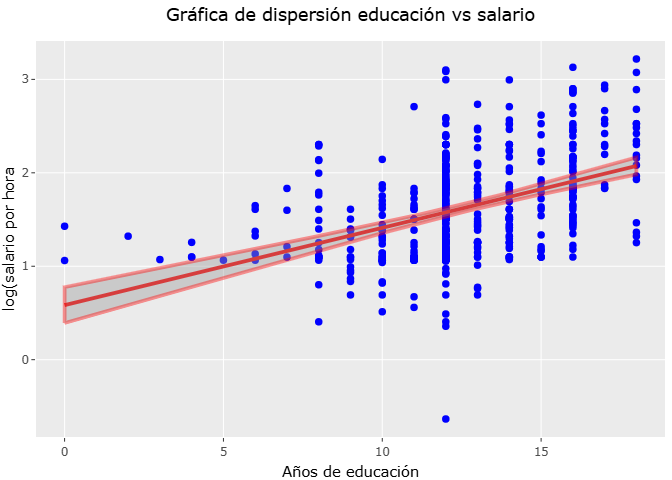
modelo_1 <- lm(lwage ~ educ, data = wage1)
#summary(modelo_1)
# library(knitr)
coefficients(summary(modelo_1)) %>%
kable()| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 0.5837727 | 0.0973358 | 5.99751 | 0 |
| educ | 0.0827444 | 0.0075667 | 10.93534 | 0 |
Prueba Diagnóstica del Modelo 1
En esta sección se presentan las pruebas diagnósticas realizadas para evaluar el comportamiento de los residuos y verificar, a partir de las gráficas y la información previa, el cumplimiento de los supuestos del modelo de regresión.
autoplot(modelo_1, which = 1:3,
nrow = 3,
ncol = 1)
Gráficas de más de dos variables
Cuando se analizan fenómenos económicos o sociales, es común que la relación entre dos variables no sea suficiente para explicar completamente el comportamiento observado. En estos casos, la representación gráfica que incorpora tres o más variables permite visualizar de manera más completa la interacción entre distintos factores y aporta una comprensión más profunda del modelo analizado.
En esta sección se emplean tanto una gráfica de dispersión tradicional con ajuste lineal como una visualización tridimensional. La primera combina información de educación, experiencia y antigüedad laboral para explorar su relación conjunta con el salario, mientras que la gráfica 3D facilita identificar patrones espaciales y posibles interacciones entre estos determinantes del ingreso. Estas herramientas permiten observar cómo múltiples características del trabajador pueden incidir simultáneamente en el salario, ofreciendo una visión más rica del comportamiento salarial dentro del conjunto de datos.

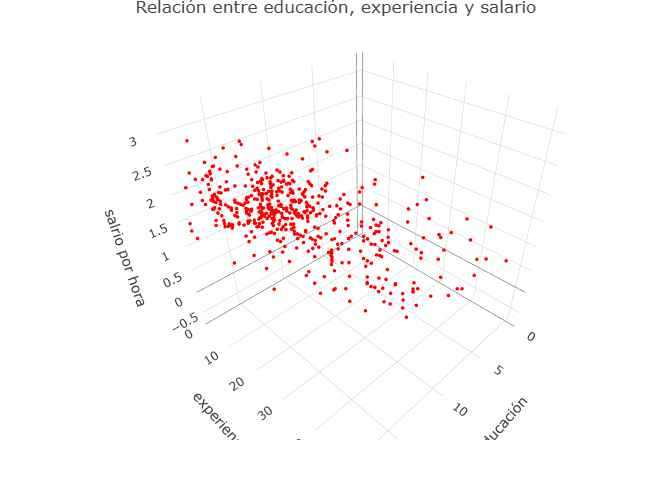
Modelo lineal 2
Este modelo tiene como propósito analizar cómo distintos factores individuales se relacionan simultáneamente con el salario de los trabajadores. A diferencia de un modelo simple que incluye solo una variable explicativa, este modelo lineal múltiple incorpora tres determinantes clave del ingreso laboral: la educación, la experiencia y la antigüedad en el empleo.
Prueba Diagnostica del Modelo 2
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 0.2843595 | 0.1041904 | 2.729230 | 0.0065625 |
| educ | 0.0920290 | 0.0073299 | 12.555246 | 0.0000000 |
| exper | 0.0041211 | 0.0017233 | 2.391437 | 0.0171356 |
| tenure | 0.0220672 | 0.0030936 | 7.133070 | 0.0000000 |


Para acceder a las gráficas interactivas y al detalle del proyecto, utilice el siguiente enlace: https://rpubs.com/MaferTenorio_/1375244


